6.4 Composing with sdfsys
6.4.1 A composition with which to compose
(6.4.1.a) sdfsys as substance
In view of the perspective of software as substance (§3.7) the works described in §6.2 and §6.3 – sdf.sys_alpha and sdfsys_beta – are presented as compositional works in the portfolio of this project; thus the italics on their names, in contrast to the conceptual entity of sdfsys. The sdfsys environment exists without the software through which it is manifest, but it is only manifest through software. At the time of writing sdfsys_beta (accessed, in the MaxMSP environment, via sdf.sys_b133.maxpat) is the most complete manifestation of sdfsys, and many other compositional works have been realised through it.
(6.4.1.b) In the context of my compositional model
The compositional model that I drew in 2010, and that was discussed in §3.7.3, is revisited now. The visual form of that model shown in §3.7.3 led to the observation that my perception of composition as a process is very similar to the 'process of action and reaction in bricolage programming' (McLean, 2011, p. 122). The first computer rendered version of the idea that was originally scribbled on paper, however, had the conceptual stages arranged in a slightly different way. It is that version that is presented here, both in order that the model may be shown again without repeating an image, and also to mention that it was rendered to .png from a thisis script; Figure 6.25 is shown here on a grey background because some the thin lines that connect the concepts in compositionModel_20100804.png , which has a transparent background, do not show well upon white.

Figure 6.25: compositionModel_20100804
Abstract thought is the primary human factor at all stages in composition. Description of sdfsys in this chapter has focused mainly on the specification of concepts, and the implementation of those concepts as interactive visual representations. There have been some rendered performances of control of data via those visual representations – §(6.2.4.d) A video walkthrough: commands and parameters in sdf.sys_alpha; §(6.3.9.e) The sdfsys_beta_xnn_video series – but these are more technologically than aesthetically motivated.
'Composing with sdfsys' implies completion of the conceptual stages shown in Figure 6.25 in order to express as music such things that cannot fully be expressed in any other way. Musicking with sdfsys is one part of it, but the sounds made as music through sdfsys can be experienced in much the same way as many other musics: either live, and I have performed sdfsys both in HELOpg and solo; or listening to recordings which may be acousmatic or with video, and this is as it was originally intended at the start of the project, though the question of whether or not to project the screen on to the acousmatic curtain continues to be explored.
Towards the objective of composing with sdfsys, there have been numerous approaches, and the pieces introduced below demonstrate the exploration of these.
(6.4.1.c) On paper and on camera
The visual appearance of the gl-ui can serve as a native notational form for sdfsys. Sketches made on paper can contain all necessary informational data to configure sdfsys either to realise something speculative, or to restore a specific configuration that was established while interacting with the system. The lines of text that form messages within the environment can be transmitted by any medium; thisis scripts are often written on paper or whiteboards that can then be photographed for portability. Sketches might include non-sdfsys-ean symbolic notation to indicate, for example, motions of parameter-sprites. Photographic or screencast images can be archived for the purposes of reproducing a specific configuration; examples are provided in the sdf_ui_on_camera sub-folder of sdfsys_b_doc.
(6.4.1.d) Introducing the included compositions
Documentation of the pieces described below can be found in the _composing_with_sdfsys folder in chapter6_sdfsys in the portfolio directories, but some elements of these works are, necessarily, located in the sdfsys_beta1 folder, along with the workings of sdfsys_beta. Alias links to such files in the sdfsys_beta1 folder are provided for indicative purposes, but if opened are unlikely to find their target on the readers' copy of the portfolio directories; the filename of the alias will indicate where the target can be found.
The composition titles, given as sub-section headings below, match the folder names in the portfolio. The descriptions continue to be of a technical nature to allow the reader to arrive at their own aesthetic understanding of the works.
6.4.2 orbit8 reading cyclephase
A rather minimal approach to claiming composition with sdfsys is to state a relationship between two modules and let the performance of the piece be a free exploration of their parameters. That is the approach taken by orbit8 reading cyclephase, and two excerpts of it being played are provided in the portfolio; for each example there is a .mov screencast recording, a .wav of the audio extracted from that recording, and a .png showing the waveform view of that audio in Audacity which was used to extract it from the .mov (one can drag-and-drop a .mov on to an Audacity project window to do that).
(6.4.2.a) 20120221_0200_cyclephase_orbit8
(1 minute 25 seconds)
This recording was published online[n6.30] with the following description:
[n6.30] At https://vimeo.com/37150649
sdf.sys_beta
space 2 load ~g.r.orbit8
space 3 load ~g.w.cyclephase
spaces network mode 0 (matrix connections): 3 => 2
~g.r.orbit8 has eight read-heads/peek-particles fixed to a circular path around a common center; each has radius size, frequency (cycles per second), and amplitude (multiplier applied to the peek'ed data) attributes/parameters. There are also master gain, slew time and center point parameters/attributes. None of these, however, are changed during this short video.
~g.w.cyclephase has one write-head/poke-particle which moves on the data matrix plane along a path determined by two frequency values: one to set the cycles per second of an circular orbit (this is the phase part of the name), while the second sets sinusoidal modulation of the particle path radius (the cycle part of the name). A third frequency type parameter is for another sinusoidal oscillator which provides the values to be written to the data matrix at the location of the particle. There are also slew time and trace parameters/attributes.
In sdf.sys_alpha what is now ~g.w.cyclephase was called tildegraph but that name has since been reassigned to refer to the general concept at play here; that of graphical data read|write/peek|poke on a plane; the name inspired by the harmonograph of the nineteenth century plus the many meta- uses of the word, and symbol, tilde. The frame rate in sdf.sys_beta dropped by half when the QuickTime screen recording was started to record this video (too many other applications running is one reason for this). When the frame rate drops below about 10fps the interaction becomes less fun; thus the short duration of this video.
(6.4.2.b) 20120222_orbit8cyclephase
(2 minutes 22 seconds)

Figure 6.26: 20120222_orbit8cyclephase.mov
(6.4.2.c) ~g.r.orbit8
There is also an example of orbit8 reading cyclephase within a more technical demonstration at the following file-path:
-
…/chapter6_sdfsys/_beta/sdfsys_b_doc/sdf_ui_on_camera/MVI_0425_trimmed_h264.mov
- (5 minutes 57 seconds)
The recording of that video identified a bug in the ~g.r.orbit8 patch: the xdim sprites that control the gain of each peek-operation-orbit allowed for negative values to be entered by dragging the sprite off the left edge; this has since been fixed so that the value is clipped to zero.
6.4.3 febandflow
(1 minute 39 seconds)
Another approach to composing with sdfsys is to allow sdfsys to function as an instrument, to record digital audio of it being played, and then to work with that digital audio as one may with recordings of any instrument.
In febandflow[n6.31] a multi-track recording was made comprising four stereo tracks, and these are then combined to a stereo mix. My motivation for this recording of febandflow included a particular exploration of rectilinear representations of digital audio again. The four stereo-tracks that were recorded have been exported as an eight-channel .aif file which has been used in a prototype multi-track sonogram visualisation; this work is described in a video that includes presentation of the febandflow through my 'jit fft colour test' patch[n6.32] (Figure 6.27):
[n6.31] The title febandflow was originally used to encompass a number of compositions that shared some common elements, but I have decided to apply the title to febandflow as described in this document, in spite of the potential confusion that this may cause if these pieces are revisited in future work.
[n6.32] Also described online at http://sdfphd.net/a/doku.php?id=jit_fft_colour_test
-
chapter6_sdfsys/_composing_with_sdfsys/febandflow/febandflow_jitfftcolourtest06.mov
- (5 minutes 53 seconds)

Figure 6.27: febandflow_jitfftcolourtest06
6.4.4 five four three
(6.4.4.a) Multiple layers of abstraction
The spatio-visual premise for five four three began as a sketched sequence of thisis commands; the sequence of sketches can be seen in the fivefourthree_whiteboard sub-folder of this works folder in the portfolio directories.
To render that sequence of commands in time, rather than have the thisis drawing be rendered almost instantly in sdfsys, I implemented the typewriter model (see below).
As well as a scripted sequence for setting up sdfsys and drawing via thisis commands, this composition also includes meta-patch sub-processes that algorithmically control parameters of the loaded modules in sdfsys.
(6.4.4.b) The typewriter model
Adding another layer of abstraction to working with sdfsys, I designed yet another text file based scripting system, and called it the typewriter model. The typewriter model is again based on the idea of a script being read one line at a time, but rather than parsing each line as fast as possible it will generate 'keyin' messages for the sdfsys text editor; the result is meant to give the impression text being typed, albeit at a mechanistic rate. The typewriter model also has syntax for sending messages directly to different parts of sdfsys and the meta-patch.
In the version of the typewriter model that is used for five four three the .txt file script is written with coll compatible formatting: that is that each line starts with an integer followed by a comma, and then ends with a semicolon. Writing, and editing, a script in this way reminded me of programming in BASIC,[n6.33] and as such gives another opportunity to reflect on the history of computer music. Perhaps one day I will regress further to implement a hole-punch syntax, but in this project I did progress to improve the usability of the type writer syntax.
[n6.33] Although I did not go as far as to add a GOTO syntax method, there is syntax by which a line may cause the message of a different line to be parsed in its place.
(6.4.4.c) fivefourthree_20120208.mov
(2 minutes 45 seconds)

Figure 6.28: fivefourthree_20120208.mov
6.4.5 penhexsepoct
(6.4.5.a) Scripted start
Adding a text_to_coll patcher to the typewriter model meant that scripts for that model could be written in .txt files without requiring line numbers to be manually maintained. The script saved as penhexsepoct.txt is written for the typewriter model and can be run by the implementation of that model in penhexsepoct.maxpat; to run the .txt script, drag-and-drop the file from the operating system's file browser to the blue-bordered dropfile object at the top of penhexsepoct.maxpat, reboot sdfsys, then click go . . . and watch the gl-ui.
The script is complete when the fourth group of points has been put (the gl-ui will look as in Figure 6.29). Performance of penhexsepoct then continues as a free exploration of the points that have been put.
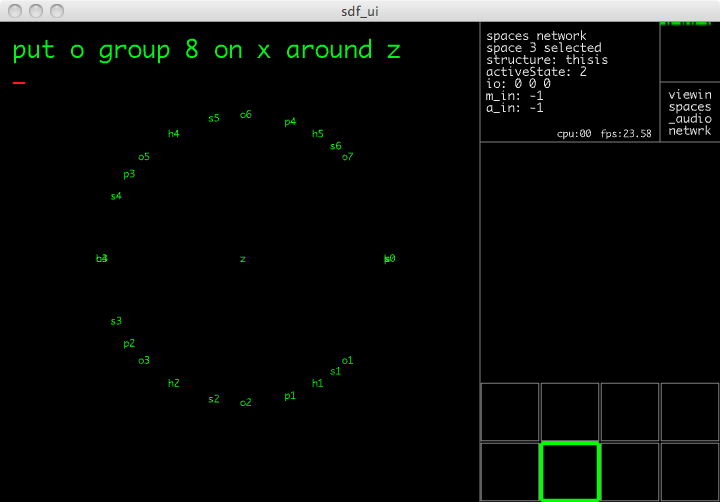
Figure 6.29: penhexsepoct
(6.4.5.b) penhexsepoct_20120427
(2 minutes 45 seconds)
Audio recording from a performance of penhexsepoct is provided – 20120427_0300.wav – along with a .png (see Figure 6.28) to show the configuration of sdfsys, including the shape of the data being read as audio, when the recording was made. The rhythmic structure of the music in that recording could be recreated by programming sdfsys with the commands shown in that .png image.
Figure 6.30: 20120427_0311.png
6.4.6 more cogmos
(6.4.6.a) Using rtuis
The typewriter model is based only on qwerty-like input to sdfsys, with some backdoor routes being used to do things like set active state values; it has no concept of the mouse, and scripts written with it, such as in five four three, would prompt the human to perform mouse actions for moving frames in the spaces network area to establish connections. It was after this that the rtuis aspect was added to sdfsys;[n6.34] more cogmos began by exploring the use of the rtuis namespaces to automate the starting sections of a composition.
[n6.34] See §(6.3.9.a)
(6.4.6.b) Recorded interaction
Using the rtuisrec sub-patch of sdfsys_beta, the live coding of modules being loaded and configured in the spaces network area of the gl-ui was recorded. The recording can seen in rtuirec_cm00.txt which can be read by the seq~ object, and can be replayed – over approximately two minutes – to have sdfsys be configured the same again. That, however, was only the first step in the composition of more cogmos: the next step was to take only the necessary lines out of that .txt file and make a meta-patch based on them.
(6.4.6.c) more_cogmos.maxpat
Although it is clear from the appearance of this maxpat that it was a work in progress, it had fulfilled its first remit of automating the start-up sequence based on that rtuis recording. The composition, however, then took on a different trajectory.
(6.4.6.d) more_cogmos.txt
A human targeted text score for more cogmos has been written and saved as more_cogmos.txt, and a copy of it is presented here:
more cogmos
by samuel freeman, 2012--2013
using .maxpat files found in the sdfsys_beta1 folder
Mac OSX 10.6.8 and Max 5 recommended
begin
1. in the MaxMSP environment, switch on DSP
2. open sdf.sys_b133.maxpat
3. when ready, run more_cogmos.maxpat
4. wait whilst the spaces network is configured
5. when the text-buffer is cleared, the setup is complete
6. use thisis to draw a cog
7. use the shape of that cog as the basis for making sound
8. make a recording of the sound being made (either audio or audio-visual)
9. the recording can be split into sections, to be saved as separate files
10. if split into sections, then some sections can be deleted
11. if split into sections, then keep the original sequence of the sections
12. present the recording(s) with the date and time of when the recording was
made within the filename(s), using the format YYYYMMDD_HHMM
end
(6.4.6.e) 20121120_0040
Comprising three videos that are to be played in sequence:
The videos are sections of a live screencast recording, recorded via QuickTime Player 10.0 (Apple); the originally recorded session was approximately 13 minutes duration, and the sdfsys_beta performance had started some time before the recording began.
It is recommended that if one has time to experience this version of more cogmos more than once, then one should listen to the audio only version first. That way it is possible to hear the sound as sound in an acousmatic way. The audio-visual experience of this composition is quite different because the soundmaking process can be seen in full technical detail, and there is the human aspect of also being able to see the mouse pointer moving, which creates a different type of anticipation during the piece. The audio only version of those three parts in one file is included as:
-
(9 minutes 34 seconds)