3.5 Gramophone_005g
Opening gramophone_005g.maxpat and clicking on the large, green coloured, button labelled 'click here to start' will start performance of what is considered the first complete composition to be presented in this document – as opposed to the formative studies discussed above. The title gramophone_005g is rather cumbersome, but the work has evaded my efforts to denominate beyond the reality of its inception; the short form g005g was adopted in the naming of exported audiovisual files to exemplify the work, and so that can also be borrowed as an abbreviated title for the piece.
It is advised to ensure that audio output of MaxMSP is working before clicking on the start button. Although the piece is programmed to switch DSP on at its start, it cannot check that an appropriate driver is actively selected, nor that stereo speakers are present after the output of the DAC. There are always a few seconds of silent inactivity after the fullscreen display of the work has been initiated, and before the soundmaking begins; this short pause is intentional within the composition, but it does mean that if there is something wrong with the DSP settings, or similar, then it may take a little longer to identify as one waits for the end of that silent period.
[n3.30] I am reminded both of experimentation such as seen in a video featuring a record player retrofitted so that an 'Angle Grinder was used as the drive' (Extreme Speed Record Player, 2012), and also of reading about Karlheinz Stockhausen's high-speed rotating speaker system that was controlled from the other side of a 'safety-plated door' at variable speeds 'up to 24 rotations per second' (Br?mmer, 2008, p. 15).
Compositionally this piece is predicated on sequenced control of the three stylus abstraction parameters that have been described above. Subjectively pleasing parameter value combinations, and transitions between such, were identified through experimentation with the model, but rather than score a fixed trajectory between these, the approach adopted was toward a more 'open outcome' (see Jansch, 2011, chapter 4). The composition is an exploration of the unplanned-for audiovisual possibilities found in the conceptual modelling of a gramophone manifest in software; in particular the shapes and sound-forms created when that model is pushed beyond the range of motion expected of the original technology.[n3.30] To some extent the choices made in controlling this software implementation of the conceptual model are arbitrary: the numbers used and their interrelatedness have been crafted according to subjective personal preference and intuition, without theorised connection to the gramophone-ness of the work nor to anything else beyond experience of the in-progress software as an interactive medium. The piece developed through careful tweaking of interrelated aspects in order to provide an open outcome structure that maintains identity as a fixed entity whilst being able to surprise even its author, and thus include an element discovery at each performance. The idea of a thing that is both always the same and every time different continues to be important.
As described below, the control value sequences that play through during the piece are generated when the maxpat is opened. This means that the same control sequence can be performed multiple times, but only until the patch is closed; a new sequence is generated when it is next opened. Duration of g005g is just over one minute, and it is recommended that more than one control sequence be generated and presented – the patch (re)opened and run more than once – in order to provide the possibility of appreciating the different-same-ness.
Within the g005g system, the control data sequences cannot be conveniently saved/recalled: the option to capture the data from now for use later has not been programmed in to the software, in the same way that an image output feature was deliberately omitted from the visyn system. Audiovisual recordings of performances have been made, and while they serve a number of functions, they suffer variously and are but shadows of the work.
3.5.1 Sequence generator
Setup for performance of the piece begins when the patch is opened in the MaxMSP environment: loadbang objects trigger the algorithmic generation of six lists: for each of the three stylus parameters there is a list of parameter values, and also a list each of transition durations that are used when stepping through the parameter values. After being generated, the values within each of these lists are reordered; the reordering includes randomisation (using zl scramble) for parameter value lists. For each of three stylus parameters, the lists of values and durations are then formatted together for storage as a collection of messages in a coll object. As an example, Figure 3.21 shows the sub-patch that generates the collection messages used for the g_mult parameter; note that the annotations of 'target range' were developmental notes, superseded by refinement of the piece. The collections of value-duration pairs are stepped through as the piece is performed.
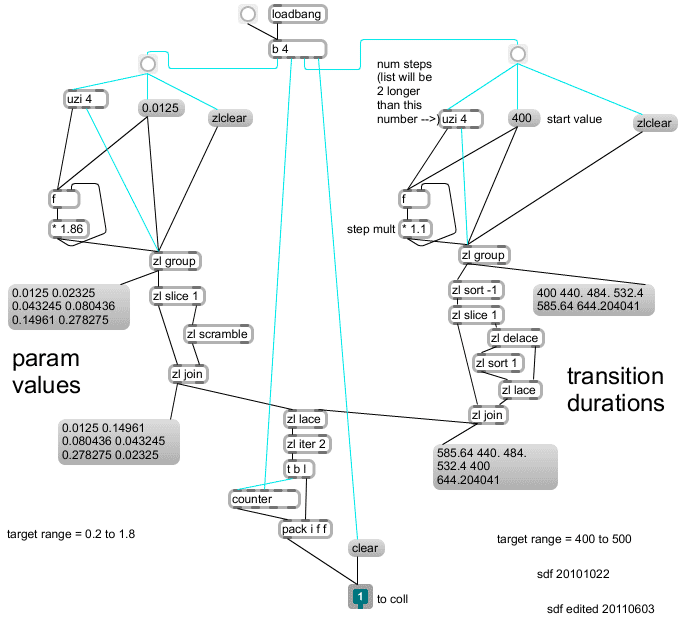
Figure 3.21: set_g-mult_seq
(3.5.1.a) List generation
Generation of each list (before reordering) is determined by a set of three numbers: a start value (s), a multiplier (m), and a number for the length of the list (l – which is the same for both of the lists that belong to a stylus parameter). The following table shows the numbers that were fixed upon after a repetitive process of interactive trial-and-improvement to 'tune' the software system:
| Stylus Parameter (length of list, l) |
Parameter Values | Transition Durations | ||
| start (s) | multiplier (m) | start (s) | multiplier (m) | |
| g_mult (6) | 0.0125 | 1.86 | 400 | 1.1 |
| g_a (12) | 0.1 | 1.5 | 320 | 1.1 |
| g_dur (44) | 2 | 1.25 | 2 | 1.2 |
Although the algorithm to generate the lists was conceived in maxpat form – as illustrated in Figure 3.21 above using message, zl group, uzi, f and * objects – it can be expressed more mathematically as the list L in which:
Ln = Ln-1 · m
where n is in the range of zero to one less than l, and:
L0 = s
It is difficult to put into words the way that I relate to algorithmic concepts when composing, but my thought processes are perhaps somewhere between the two forms of notation demonstrated above; somewhere, that is, between a visual data flow and an abstract sequential algebraic representation of number patterns. It seems significant to consider this because the non-lingual, non-material, abstract number level of the human mind is the realm of much creative thinking.
The algorithm/formula used to generate the lists is quite elementary: indeed most of my work is to do with interconnection of simple ideas. Further, with a more analytical reevaluation of this material an even more simple notation of the same algorithm has been observed, and it is, perhaps, a much more elegant representation of the list generation:
Ln = s · mn
With this formulation, the nth value of the list can be determined without requiring knowledge of the previous value. In contrast, the form in which the list generator was conceived is that of a sequential process that is thought of as to occur in the time-domain, albeit calculated very quickly by the computer. Whereas the mn version could just as well be implemented, in MaxMSP or any other environment, the Ln-1 version is more aesthetically aligned to the intention behind this part of the system. Generation of the lists is an automated but linear process.
(3.5.1.b) List value reordering
Reordering of the numbers within each of the six lists is carried out by a number of different zl object cascades within the maxpat. There is enough similarity amongst these six different cascades – two of which can be seen in the illustrated sub-patch (Figure 3.21) above – to be able to represent the list item order processing as shown in the two following flow-chart representations. Figure 3.22 represents generation of parameter values lists, and Figure 3.23 is a representation of the transition duration lists. Although these such flow-charts are intended to represent aspects of my work in a non-language-specific way by calling upon general computer programming concepts, in these flow-charts include the specific 'mode' names of the zl objects ('slice','scramble', etc).[n3.31]
[n3.31] Description of the modes can be found in the MaxMSP documentation for the object, also online at http://www.cycling74.com/docs/max5/refpages/max-ref/zl.html

Figure 3.22: g005g_reordering_paramVal

Figure 3.23: g005g_reordering_transDur
(3.5.1.c) Layers of abstraction
As a brief aside to the discussion, an acknowledgment towards the concept of 'layers of abstraction' which has been recurrent as an aesthetic reference throughout this project.
Notice, above, repetition within the words that describe how the g005g piece is constructed. Within the stylus abstraction of the gramophone model the g_mult and the g_a parameters are both multipliers; more multipliers are used in generating lists for sequential control of that model. The third parameter of the stylus abstraction, g_dur, is a duration value (expressed in milliseconds); lists of duration values are generated to control the transitions between values during the sequenced performance. In describing the way that those lists for the sequential control aspect of the composition are generated it has been shown that a sequential algorithm is used. The same concepts are occurring at different layers of abstraction, and the concept of layers of abstraction becomes an important element of the aesthetics of the project in development of later works.
The works, cited above, by Iglesia entered into the research of this project only after the identification of an article, from Organised Sound 13(3), as significant to aesthetic underpinning of the project (Iglesia, 2008, p. 218):
At the very start, the elements of computer music were most referential of their own mechanical properties: the most basic element, the square wave, is made by turning one bit on and off. Every advance in digital audio technology has added a distance between our user concept of sound manipulation and the actual operation of raw bits. Ones and zeroes have been abstracted to machine code through the RISC architecture, opcodes and assembly language, which have been abstracted to text programming languages through interpreters and compilers, and onwards to graphical user interfaces, physical interfaces, and so forth. The creation and traversal of these layers of abstraction is itself the history of computer evolution, and, with it, the history of techniques for making and controlling computer sound.
3.5.2 Manifestation of g005g
Because each of the parameter control message collections is of a different length, the shorter two collections will be iterated through more than once during a single performance; the ending of the piece – in which the amplitude of the output audio is faded out – is triggered when the last message of the longer g_dur collection is reached. Although the g_a and g_mult parameter values will occur multiple times, each occurrence of a specific value will coincide with different values of the other parameters. The method by which the parameter values are triggered from their collections during the piece is shown as a flow-chart in Figure 3.24.
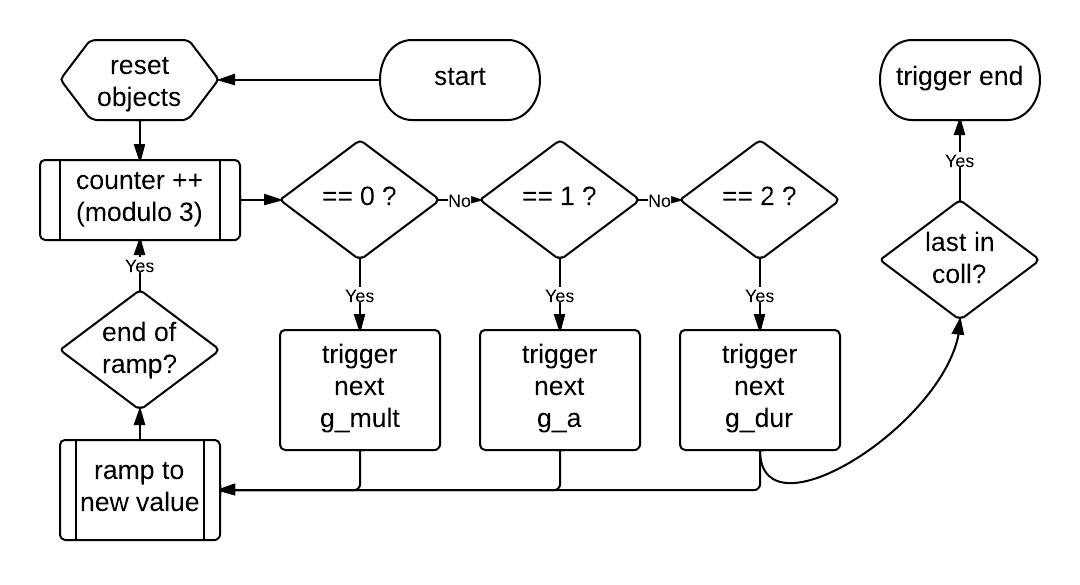
Figure 3.24: g005g_trigger flow
Often the position of the playback-heads will be set to coordinates that are beyond the bounds of the data matrix, and so the audio output includes many silent periods. Although the durations that control parameter value transitions are the same every time, the values that control where the stylus path sits on the plane will occur in different patterns, and the manifestation of this in time is that those the silent periods are indeterminate and may each be of anything from as short as a few milliseconds – in which case there is a granulation of sound produced – up to as long as several seconds: a six second silence has been measured in the fifth example audio recording of the piece (see §3.5.4.b below).
[n3.32] It is beyond the scope of this project to discus at any depth the optical illusions induced by these processed noise images, but the idea of visual 'form constants' is again brought to mind (mentioned, with citations, in §3.4.2).
Audio input data recording is not a feature of g005g. Cell values of the data surface are instead all set, once, by the output of a jit.noise object as modified by jit.expr, when the patch is loaded. When composing this piece I was still new to the Jitter realm of the MaxMSP environment, and I was studying to learn about more of its objects. One of the example expressions from the jit.expr.maxhelp patch was found to give a pleasingly circular formation when processing a matrix filled by jit.noise as illustrated in the middle display within Figure 3.25.[n3.32] The dark area in the centre is caused by lower values in the cells of the matrix there; it was decided to reverse that light-to-dark-inward-ness in the visual form to have, instead, a dark-to-light-inward-ness thus to approach greater values correlating to greater amplitude in the sound as the styli move inward.
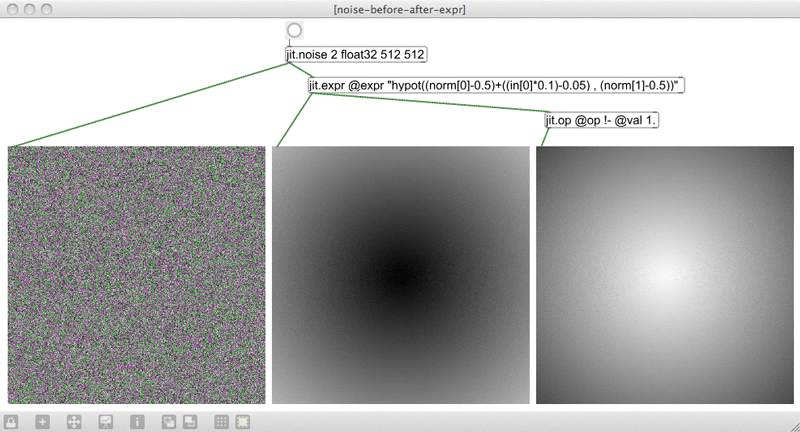
Figure 3.25: jitnoiseexpr
The prototype of the gramophone model demonstrated in version _002_a used the blue layer of an RGB display to show the recorded audio data, and the trace of the recording-head while writing that data, but now that a static greyscale data surface is in use the blue layer is conceptually available for somethings else. Perhaps inevitably, an x-y oscilloscope type trace of the audio output channels was established. This addition makes it so that the on-screen display includes visual representation of all three stages in the system: the raw data, the reading process of that data, and a projection of the sounding form of the read data.
By adding the oscilloscope type visualisation it became immediately apparent that the cells of the data surface contain only values between 0 and 1: the blue trace on screen was confined to one quarter of the plane. Audio output, therefore, would only drive each speaker across half of its available range of motion. The twitching-speakers described in §3.1.1, and referenced again in §3.3.4, are again brought to mind: here it is the unidirectional drive of the battery on the speaker that comes to mind in particular. One option to rectify the situation in the g005g system would have been to scale the data matrix to the ±1 range, but the solution taken was to follow my first instinct at discovering the issue.[n3.33] As soon as the observation was made, a DSP sub-patch was created on-the-fly with the aim of introducing inverted copies of the output signals with modulated time delays to create a subtle comb-filtering effect.
[n3.33] Evidently I had at first assumed noise~ like output from jit.noise, even though the observed behaviour of jit.noise is perfectly logical, especially in view of Jitter's native float32-to-char mapping discussed at §3.4.5.
The DSP section of the g005g patch is shown in Figure 3.26. Notice that one of the stylus abstractions (the patch is named stylus_on_512_002) is set to re-trigger mode 1, and the other to mode 3 (the second inlet): these manifest as 'in-in' and 'in-out', as is indicated in the pop-up menu objects in _002_a, which is not as is annotated within the stylus abstraction patch. The comments within the stylus abstraction patch indicate the behaviours that were being aimed for when programming the re-triggering logic algorithm. Unless there is an aesthetic reason to pursue exactly the self-set goals in the creation of a system, it is standard within my practice to let the unexpected outcomes influence the work. Glitch and surprise are embraced at many levels of abstraction in my work; new directions are often followed when 'errors' occur along the way. Various traces of my thought processes – such as dead-ends in data flow, and misleading comments – are often left intact within the software artefacts, especially in these early works of the project. In later works there has been more attention to the final correctness of software presentation.
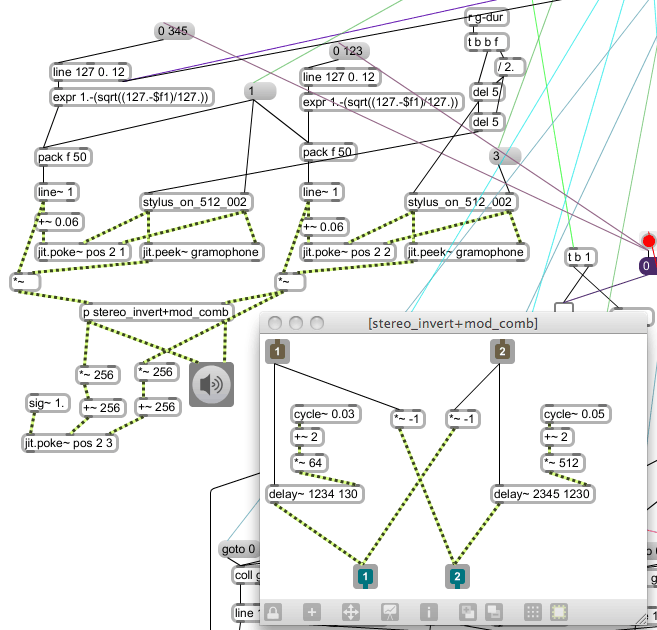
Figure 3.26: g005g_dsp
Accumulative build up of speculative patching can lead to interesting systems that are in line with original intentions, but with this style of programming there is always a risk of introducing instability. Thorough testing of the g005g system, on a variety of Mac OSX computers running MaxMSP 5, was undertaken during the composition of this work. It is full of oddities and workarounds – there are things I would certainly do different if re-coding the system now – but I believe it to be stable and consistent. Only the issues forewarned about in the second paragraph at the start of §3.5 have been found to cause problems in set up for performance.
[…]
3.5.3 Audiovisual output: open outcome and recorded examples
Video recordings of the output from g005g – created either with Jitter, or using the 'Screen Recording' feature of QuickTime (Apple) – have failed to capture that which is found in the native format. Discussion of video codecs, data compression, the reasons for colours appearing wrong (a yellow pixel becoming white for example), and other such technicalities that impact on the quality of a recording are beyond the scope of this project, and (although of consequence) are beside the point of a video's shortcomings. The significant point to emphasise is that video recordings of g005g performances – and those of earlier versions of the gramophone model composition – are not meant to represent the work itself: the software-based system, native to the MaxMSP environment, is the artefact that best represents this composition.[n3.34] Video recordings do, however, serve well to document the work, and they are accessible in situations where the software itself cannot run: a video will play, for example, on a tablet or telephone device upon which the MaxMSP RunTime is not available.
[n3.34] From the descriptions and diagrams provided in this document there is enough information to reconstruct the composition in another environment.
Audio recordings of the work are also both useful and redundant in representing the work; the emergence, in this perspective, of a potential paradox raises some important aesthetic questions. One of these questions – already addressed in part – is to do with fixity: performances of g005g recorded and saved as sound-files are useful for examination of the audio output (see §3.5.4 below), but as a means of dissemination, any fixed media format completely fails to capture the essence of the work. Adam Jansch explains the problem whilst indicating its context in twentieth-century music, as exemplified in works by John Cage (Jansch, 2011, pp. 50–51):
[n3.35] Jansch cites: Tone, Yasanao, 'John Cage and Recording', Leonardo, Vol. 13, Groove, Pit and Wave: Recording, Transmission and Music (2003), 13.
[n3.36] At this point Jansch provides the following footnote (p. 51): 'Ironically, as wax cylinders were recorded in batches of different performances, and not mass-produced copies of one performance, they can be seen as the least fixed format of such records.' The gramophone disc superseded the wax cylinder, and it seems that my compositional extension to the conceptual model here has inadvertently taken an extra conceptual step back in time.
by recording an open outcome work, one particular rendition becomes frozen and exactly repeatable, thereby undermining the whole point of that work being open, as highlighted by Yasanao Tone in his writings on Cage's indeterminacy.[n3.35]
Despite improvements in quality and usability throughout its life, the one characteristic of the record that has remained fixed is its fixity, a facet left untouched by progress since the wax cylinder.[n3.36] To develop the idea of an open outcome record further, therefore, one must challenge this aspect of the record, imagining a new generation of record where the media does not represent the final form of a work, but instead a pool of materials, a process or an algorithm which, when put into action, produce the final form of the work.
Audiovisual recordings of an open outcome work such as g005g are only ever documentary evidence of the work that actually exists in another form (as software in this case). There is, in my opinion, a great danger of the recordings being mistaken for the work itself; the likely inferior audiovisual quality of such recordings, and their inherent fixity – allowing multiple viewings of identical data – detract from the aesthetic properties of the piece. While these are important issues that have been considered, they also detract from the focus of this project.
Another question to be addressed, arising from the way that such audio recordings are both useful and redundant (and the potential paradox of this), has to do with the audiovisual-ness of the g005g piece itself. Clearly this piece has been created with audiovisual performance in mind: the audience are presented with layered visual representations of the raw data used to make sound, of the soundmaking processes acting up upon that data in real-time, and of the sounding output itself. These visual representations were implemented in a system that was then 'composed for', more than it was 'composed with'.
During the compositional development of this work, all interaction with the audiovisual manifestations was via patching in the MaxMSP environment. Whereas that mode of working is familiar and comfortable, the intention of the project as a whole is to move toward systems of visual representation that were more directly interactive. The directive of the project is to explore the visual representations of sound in software during the composition of new music. The gramophone model, and the g005g piece created upon that model, are important steps toward a new way of working with sound on screen during the creative process, but they do not yet embody that goal. As was approached earlier (§3.4.5), an ideal software environment, for me, would have an integrated display GUI comprising visual representations of data, of processes, of system parameters, and so on. In such a system it would not be required for the visual gaze, and cognitive constructs with it, to switch between standard and bespoke environments during the act of composition. A version of that goal has since been realised in the creation of sdfsys.
Thinking about the compositional process, and the practice of creating custom software environments in which to compose – new software systems within existent environments that restrict possibility down from general purpose programming to a particular set of possible interactions – has lead toward questions pertaining to what acts may be called 'composition' in contrast to those that may be called 'programming'; is it possible to distinguish the two in a practice such as is found in this project? (See §3.7).
To conclude discussion of g005g, fixed audio examples recorded of this open outcome work are presented (§3.5.4), and the usefulness of such media demonstrated: waveform and spectrogram visual representations are employed to support above statements made about the piece. The following section (§3.5.5) then contextualises the sonic character of g005g by describing how the noises created in exploration of the gramophone model patches ignited a dormant desire to have computer control over particular types of sound known from analogue electronic audio technology.
3.5.4 Shapes in time: using rectilinear views of recorded audio output
[n3.37] Saved with the filename component _x to signify that these are exported examples of the piece (e.g. g005g_x1.aif). The files are located in the folder named 'exampleAudio' within the 'model_of_a_gramophone' directory.
[n3.38] Audacity is free and can be found online at http://audacity.sourceforge.net/
Sound-file recordings of the audio output of g005g were made[n3.37] to facilitate a number of analytical motivations; three types of comparison will be described here using images – created in the GUI of Audacity[n3.37] – of data from various sound-files.
(3.5.4.a) Difference (and the samenesses within)
Firstly, in order to confirm that each generated control sequence does indeed produce a different rhythmical structure – in terms of sounding, and silent periods – recordings of four different control sequences were made and viewed together in Audacity: Figure 3.27 shows these four different renditions displayed using the 'Spectrogram log(f)' view mode.
-.png)
Figure 3.27: g005g_x1-x4(spectroLog)
The periods of silence are caused by the stylus read-heads being out-of-bounds (§3.5.2), and it is the randomisation of the parameters controlling the size and speed of the stylus paths that cause indeterminacy in the rhythmic structure. Timing of the control changes, however, is entirely deterministic (§3.5.1), and closer inspection of these four examples, side-by-side in the illustrated way, can reveal the underlying temporal structure that is common to all renditions. A seven second period from around the middle of the piece is shown in both of the following images: the same seven seconds of data is shown both with the spectrogram view (Figure 3.28), and with the waveform view mode (Figure 3.29). To help identify where those predetermined time-domain boundaries manifest in these recordings some 'label track' annotation is included, and the highlighted selection indicates on such period.[n3.39]
[n3.39] To make the duration boundaries more clear in this particular illustration, the four sound-files were offset within ≈50 milliseconds so that there is better visual alignment at 33 seconds. This adjustment is not so artificial as it may seem when one considers the potential build up of lag between messages in the MaxMSP environment (a 'feature' of the environment that I embrace for the 'fuzzy' conception of temporal precision that it can introduce). Such adjustments were not applied to any of the other examples.
mid7sec-.png)
Figure 3.28: g005g_x1-x4(spectroLog)mid7sec
mid7sec-.png)
Figure 3.29: g005g_x1-x4(wave)mid7sec
(3.5.4.b) Sameness (and the differences within)
Secondly, to complement the above inter-rendition comparison of difference (and the samenesses within), comparisons of sameness (and the differences within) are provided by taking multiple recordings of the same control sequence (by running the performance more than once without closing the patch). Two _x5 recordings were made, and are illustrated in Figure 3.30.
-.png)
Figure 3.30: g005g_x5ab(spectroLog)
Four recordings were then made of a sixth control sequence (_x6) with the aim that more instances of the same sequence may provide better opportunity to see the small differences occurring between those; in Figure 3.31 the waveform view mode of a four second section is shown, and empty label tracks are used to help visually separate the stereo sound-file tracks. The period illustrated in Figure 3.31 contains a number of slight deviations from samenesses, and although most of these would be inaudible one can know that they are there.
4sec-.png)
Figure 3.31: g005g_x6abcd(wave)4sec
(3.5.4.c) Pre- and post-DSP
The third analytical comparison utilising visual inspection of audio output data from g005g is to examine the affect of the DSP that is applied to the raw output of the stylus abstraction read-heads within the system (the DSP patch can be seen in Figure 3.26, at §3.5.2 above). A sound-file comprising four-channels has been recorded: the raw (DSP bypassed, thus unipolar) output of the two read-heads is written to the first two channels, while the normal (bipolar processed version of that data) output is written the other two channels of the sound-file. In Audacity these four channels are then presented as a pair of stereo-tracks, and an empty label track is used between them to provide vertical spacing for better visual separation of the pre- and post-DSP signals.
Another seven second excerpt has been chosen for this comparison: looking first at the spectrogram view (Figure 3.32) the temporal interplay of the two styli, and their differing spectral content can be seen in the upper stereo-track; the frequency-domain content (a summation of the raw signals) is the same in both spectrograms of the lower stereo-track. Looking at that same seven seconds of data with the waveform view mode clearly (Figure 3.33) shows how the types of wave shape, that have already been shown in the examples above, relate to the raw data from the read-heads. Remember that the first stylus abstraction is set to the 'in-in' re-trigger mode, while the second uses the 'in-out' mode; these explain the vertically-cut-off shape in the uppermost waveform view in comparison to the palindromic counterpart in the waveform view of the second channel.
46-53(spect)-.png)
Figure 3.32: g005g_x7(b+n)46-53(spect)
46-53(wave)-.png)
Figure 3.33: g005g_x7(b+n)46-53(wave)
3.5.5 Contextualisation of the sound
The conceptual and practical steps taken to create g005g have been discussed in detail with particular attention to the soundmaking processes, but details of the most important factor – the sound itself – have received little mention. Performance of the piece itself can be triggered by the reader who has access to the software, and recorded audio examples are provided, allowing the reader to hear the sound-world created and to construct their own associations from their perceptions of it. Nonetheless, to contextualise the sound of g005g, a fourth type of analytical comparison is formed from audio data included from my earlier electroacoustic. This comparison aims to bring into light what were aural intuitions, at the time of programming/composing g005g, in a way similar to those visual inspections presented above.
The joy with which this gramophone-model-based composition was pursued can, to some extent, be attributed to the similarities that I heard of the sounds being produced by the established soundmaking method in the software to the soundscapes that I know from experience with the control of feedback loops within an analogue audio electronics. Contextualisation in Collins (2006, p. 182) connects the so-called 'no input mixing' instrument to David Tudor[n3.40] who, in the early days of electronic music:
[n3.40] The reader may recall (from §3.3.7) that Tudor was also involved in the earliest laser-light visualisations of sound.
used mixer matrices to combine relatively simple circuits into networks that produced sound of surprising richness and variation. Instead of simply mixing a handful of sound sources down to a stereo signal, Tudor interconnected sound modules with multiple feedback paths and output channels. The recent rise of the “no input mixing” school of internal machine feedback has exposed a new generation of musicians and listeners to the possibilities of matrix feedback.
When faced with a system that has both inputs and outputs of the same type (in terms of content or connector, or both), experimentation with feeding those outputs back to the inputs seems inevitable. In addition to the richness of its aural manifestations, circularity in signal flow has aesthetic appeal.
Feedback loops have long been held with high regard in the praxis of my musicking; I have constructed, performed with, and recorded sound from various electroacoustic systems based on signal path loops, often hybridising laptop and analogue technologies. The sounding character of one such system, a particular analogue no-input-mixer configuration without additional processing, is typified by a recording that I made in 2008. That recording was included, with the title phonicMX881, on a self-distributed audio-CDR in that year; that collection of works is now available online as a SoundCloud 'set'.[n3.41] Seven short excerpts (durations in range of three to ten seconds) are included in the portfolio directories[n3.42] as .wav files with name-matched .png images showing spectrogram and waveform views together for each example.
[n3.41] Find the full phonicMX881 recording online at https://soundcloud.com/chai/phonicmx881?in=chai/sets/ingle-nook
[n3.42] Folder path: […]/model_of_a_gramophone/exampleAudio/phonicMX881excerpts
The similarity that was perceived between the sounds being made with the gramophone model and the sounds of the 'no input mixing' instrument was met with some amusement, when getting to know the capacities of that software; it seems that regardless of my aesthetic motivations or technological approach, I continue to arrive at a particular place in sound. Through such aurally observed similarities an emotional connection to my new soundmaking process was formed.
The similarity that was perceived between the sounds being made with the gramophone model and the sounds of the 'no input mixing' instrument was met with some amusement, when getting to know the capacities of that software; it seems that regardless of my aesthetic motivations or technological approach, I continue to arrive at a particular place in sound. Through such aurally observed similarities an emotional connection to my new soundmaking process was formed.
Conceptually, however, there is little connection from the controlled feedback soundmaking method to the g005g composition, and there was no actual study of the similarity before 2012. It ought to be conceded that the perceived similarity of the no-input-mixer to the gramophone model's sonic character must have had an influence on the way that the sound parameters were then controlled in the programming of the composition. The changes of state between sounding textures, for example, that are either sudden or that transition in no more than a second of time, and the combinations of continuous tones and fragmented rhythms, are all general features that are shared by both the g005g work and the earlier phonicmx881 example cited.[n3.43]
[n3.43] Noted also that, while the waveforms of the phonicmx881 examples exhibit few 'silences', the extreme high or low frequency content of some periods are, indeed, heard as 'gaps' in the sound.
Visual representation of three of the phonicmx881 excepts are included as Figures 3.34, 3.35, and 3.36 below; please refer to the portfolio sub-directories to hear the corresponding audio of these and others.
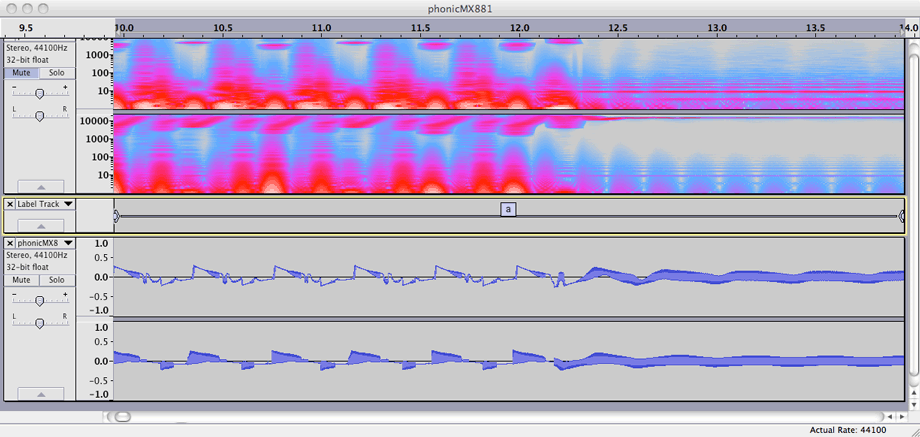
Figure 3.34: phonicMX881_a
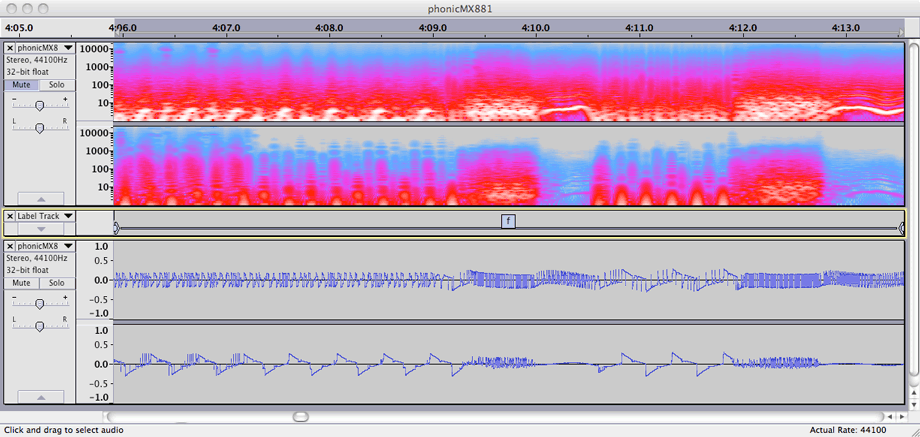
Figure 3.35: phonicMX881_f
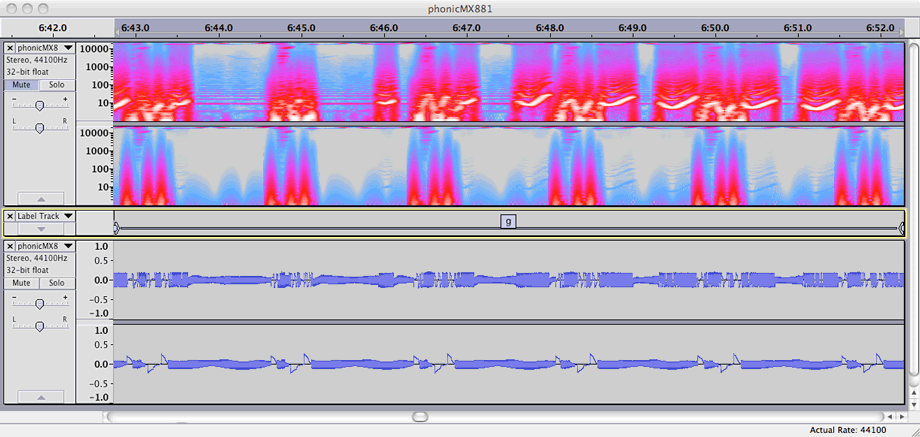
Figure 3.36: phonicMX881_g